JAMA 子刊:基于机器学习的自闭症谱系障碍预测模型的有效性
时间:2024-08-24 17:00:39 热度:37.1℃ 作者:网络
自闭症谱系障碍(ASD)是一种神经发育障碍,其表现为沟通和社交互动的困难以及有限和重复的行为模式。早期识别ASD至关重要,因为早期干预可以显著改善患儿的发育结果。然而,目前的筛查工具面临主观性强、文化差异以及儿童行为异质性等挑战,导致诊断延迟并增加家庭和社会的负担。为了解决这些问题,本研究旨在开发和验证一种基于最少背景和医疗信息的机器学习(ML)模型,用于早期预测ASD,并评估该模型的预测因素及其在临床中的应用价值。

本研究是一项回顾性诊断研究,使用了Simons Foundation Powering Autism Research for Knowledge (SPARK) 数据库的30,660名参与者的数据(15,330名ASD患者和15,330名非ASD患者)。研究采用了28项在24个月之前可获取的基本医疗筛查和背景信息,通过四种机器学习算法(逻辑回归、决策树、随机森林和极限梯度提升)开发了ASD预测模型,并在独立的数据集上进行了验证。这些模型的性能通过准确性、ROC曲线下面积(AUROC)、灵敏度、特异性、阳性预测值(PPV)和F1评分等指标进行评估。同时,使用解释性AI方法分析了各个特征对ASD预测的影响,以增强模型的可解释性。
基于极限梯度提升(XGBoost)算法开发的自闭症谱系障碍(ASD)预测模型在准确性和泛化能力上表现出色。在研究的初始阶段,模型在SPARK版本8的数据集中进行了训练和验证,最终选择的28项特征包括11项基础医疗筛查数据和17项背景信息,这些特征均能在儿童24个月前收集到。经过10折交叉验证,XGBoost模型在测试集上的ROC曲线下面积(AUROC)达到了0.895,表现出较高的灵敏度(0.805)和特异性(0.829),阳性预测值(PPV)为0.897,表明该模型在ASD预测中具备较高的准确性和可靠性。
进一步的验证实验在SPARK版本10的数据集上进行,该数据集包含11,936名新招募的参与者,其中10,476名为ASD患者,1,460名为非ASD个体。在这一独立验证集中,模型的AUROC为0.790,整体预测准确率为78.9%,其中ASD患者的识别准确率为78.9%。尽管模型在一些个体上未能准确预测(约21%),但对这些未能准确预测的个体进行深入分析后发现,未能被正确识别的ASD患者通常在社交沟通能力和社会功能方面表现出更严重的症状。尤其是错误预测为非ASD的ASD患者,其在儿童行为检查量表(CBCL)中的得分较低、IQ较高,并且在社会沟通问卷(SCQ)中的得分相对较低,这表明模型在处理症状相对较轻的ASD患者时存在一定的挑战。
在SPARK版本10的验证数据集中,通过Shapley加法解释(SHAP)值分析,发现特征如饮食行为、使用短语或句子的年龄、形成长句子的年龄、排便训练的年龄以及第一次微笑的年龄等,在ASD预测中具有重要作用。这些特征在模型的正确预测中发挥了关键作用,为ASD的早期筛查提供了有力的支持。
此外,模型在另一个独立的验证集,即Simons Simplex Collection(SSC)中的2,854名ASD个体上进行测试,结果显示该模型能够正确识别出68%的ASD个体。尽管SSC数据集中缺少非ASD个体,无法计算整体的AUROC,但这一结果仍展示了模型在不同数据集上的广泛适用性和预测能力。
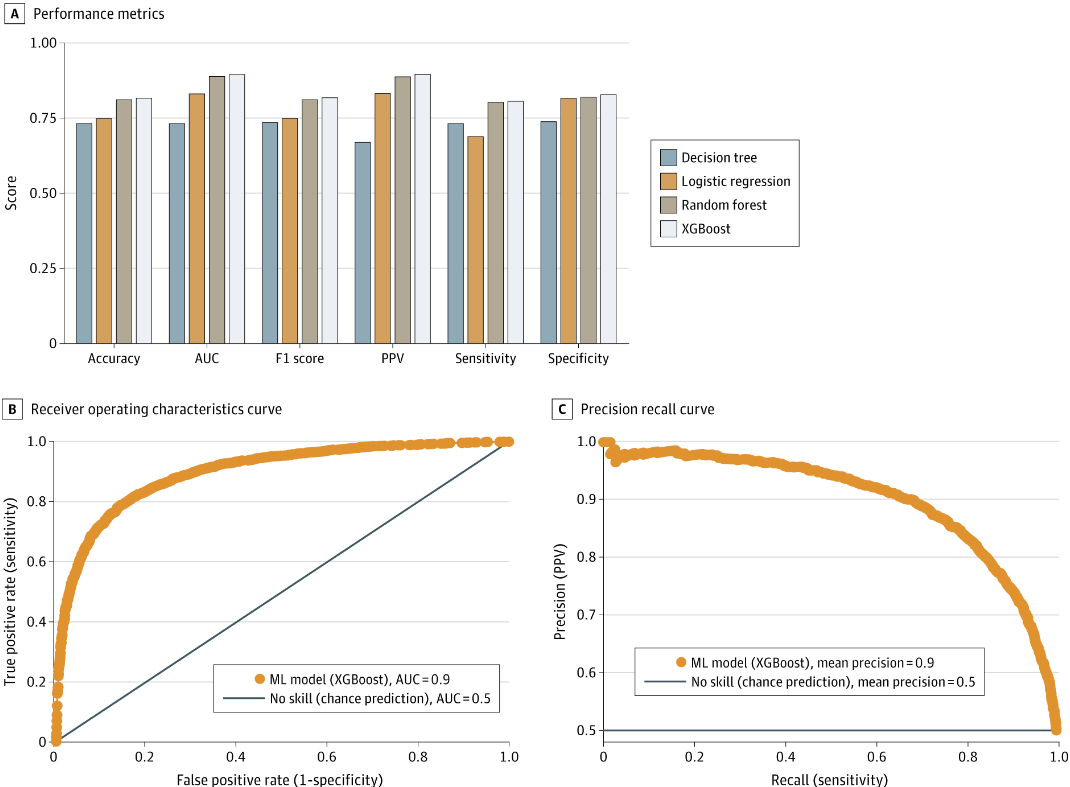
机器学习(ML)算法使用组合医学筛查和背景历史测量的性能
总体而言,这一基于XGBoost的ASD预测模型不仅在识别ASD个体方面表现优异,还展示了较高的泛化能力,能够适应不同的独立验证数据集。虽然在一些症状较轻的ASD个体中,模型的预测准确性有所下降,但模型仍能够有效识别出那些具有较明显症状的ASD患者。研究结果表明,该模型有望成为一种有效的ASD早期筛查工具,有助于提升ASD的早期诊断率和干预效果。
原始出处:
Machine Learning Prediction of Autism Spectrum Disorder From a Minimal Set of Medical and Background Information. JAMA Netw Open. 2024;7(8):e2429229. doi:10.1001/jamanetworkopen.2024.29229

