Nature Medicine:人工智能助力痴呆症精准诊断:多模态数据综合应用的突破
时间:2024-07-07 06:01:31 热度:37.1℃ 作者:网络
引言
痴呆症的鉴别诊断一直是神经病学中的一个挑战,由于各种病因在症状上的重叠,这一过程显得尤为复杂。然而,准确的鉴别诊断对于制定早期个性化的治疗策略至关重要。7月4日Nature Medicine的报道“AI-based differential diagnosis of dementia etiologies on multimodal data”介绍了一种利用多模态数据进行痴呆症病因鉴别的人工智能(AI)模型,该模型综合了人口统计信息、个人和家族病史、药物使用情况、神经心理评估、功能评估以及多模态神经影像数据,从而识别个体痴呆症的病因。研究涉及来自九个独立、地理分布广泛的数据集的51269名参与者,帮助识别出十种不同的痴呆症病因。即使在数据不完整的情况下,该模型也能保证预测的稳健性。模型在区分正常认知、轻度认知障碍和痴呆个体时,AUROC达到了0.94,在区分痴呆病因时,AUROC为0.96。对于混合痴呆病例,该模型的平均AUROC为0.78。在随机选择的100个病例中,神经科医生在AI模型辅助下的评估比单独评估的AUROC高出26.25%。此外,模型预测结果与生物标志物证据一致,其与不同蛋白病变的关联通过尸检结果得到验证。该框架有潜力作为临床环境和药物试验中的痴呆筛查工具,但需要进一步的前瞻性研究来确认其改善患者护理的能力。
痴呆症是当今最紧迫的健康挑战之一。每年报告近1000万例新病例,这种综合症以认知功能逐渐下降为特征,严重到妨碍日常生活,带来了巨大的临床和社会经济挑战。2017年,世界卫生组织的全球行动计划强调,及时和准确地诊断痴呆症是应对全球痴呆症病例数量增加的关键战略目标。鉴于全球人口老龄化和对药物试验中更准确参与者筛选的需求,痴呆症诊断的精确性仍是一项关键但尚未满足的需求。这一挑战主要源于不同类型痴呆症的临床表现重叠,再加上磁共振成像(MRI)扫描结果的异质性。随着专科医生(包括神经科医生、神经心理学家和老年护理提供者)短缺问题的加剧,改进诊断工具的必要性日益紧迫。

随着全球人口老龄化,痴呆症的发病率不断上升,早期和准确的诊断变得尤为重要。该研究介绍了一种利用多模态数据进行痴呆症病因鉴别的人工智能(AI)模型,通过整合多种数据源,提供个体化的诊断信息。
痴呆症是一种严重的认知功能障碍,影响患者的日常生活。常见的痴呆类型包括阿尔茨海默病(Alzheimer's Disease, AD)、血管性痴呆(Vascular Dementia, VD)、路易体痴呆(Lewy Body Dementia, LBD)等 。由于不同类型痴呆症在临床表现上的重叠,传统的诊断方法(如临床评估、神经心理测试和MRI等)在区分这些病因时存在一定的困难。此外,专科医生的短缺进一步加剧了诊断的挑战 。
近年来,机器学习(Machine Learning, ML)技术在医学诊断中的应用日益广泛。尤其是利用神经影像数据和其他临床信息,ML方法在识别和区分痴呆类型方面展现出了潜力。然而,大多数现有的ML方法主要关注于区分正常认知(Normal Cognition, NC)、轻度认知障碍(Mild Cognitive Impairment, MCI)和痴呆症(Dementia, DE),并未充分考虑到多种痴呆病因的复杂性和共存性 。
该研究提出了一种多模态ML框架,通过综合分析包括人口统计学信息、个人和家族病史、药物使用情况、神经心理评估、功能评估以及多模态神经影像数据等多个数据源,对痴呆症进行病因鉴别。研究数据来自九个独立的、地理分布广泛的队列,共计51,269名参与者。
数据来自National Alzheimer’s Coordinating Center (NACC)、Alzheimer’s Disease Neuroimaging Initiative (ADNI)等九个队列。这些数据集提供了大量关于患者的详细信息,包括人口统计学数据、病史、药物使用情况、神经心理测试结果和神经影像数据等。
参与者包括正常认知(NC)、轻度认知障碍(MCI)和痴呆症(DE)患者。具体来说,NACC数据集中包括17,242名正常认知个体、7,582名轻度认知障碍个体和16,131名阿尔茨海默病患者。
多模态数据包括MRI扫描、神经心理测试、人口统计信息等。MRI数据包括多种扫描模式,如T1加权、T2加权、FLAIR、DWI和SWI等,以全面捕捉脑部结构和功能信息。
模型构建
利用Transformer架构处理多种诊断数据。每种数据类型首先被转换为固定长度的向量,然后通过变换器进行综合分析,输出每种病因的概率。变换器架构的核心在于其能够有效处理序列数据,并通过自注意力机制捕捉数据中的复杂关系。
采用随机特征掩码技术处理不完整数据,以确保模型在不同数据可用性情况下的稳健性。在实际应用中,临床数据往往是不完整的,因此模型需要能够在缺失部分数据的情况下仍然保持高准确性。
通过十种不同的痴呆病因进行验证,评估模型在区分正常认知、轻度认知障碍和痴呆症个体时的性能。具体来说,模型在区分阿尔茨海默病、路易体痴呆、血管性痴呆、额颞叶变性等不同病因时表现出色。
使用包括Pearson相关系数在内的多种指标评估模型与神经科医生之间的一致性。研究发现,AI模型的预测结果与神经科医生的诊断具有高度一致性,尤其在复杂病例中,AI模型的辅助显著提高了诊断的准确性。
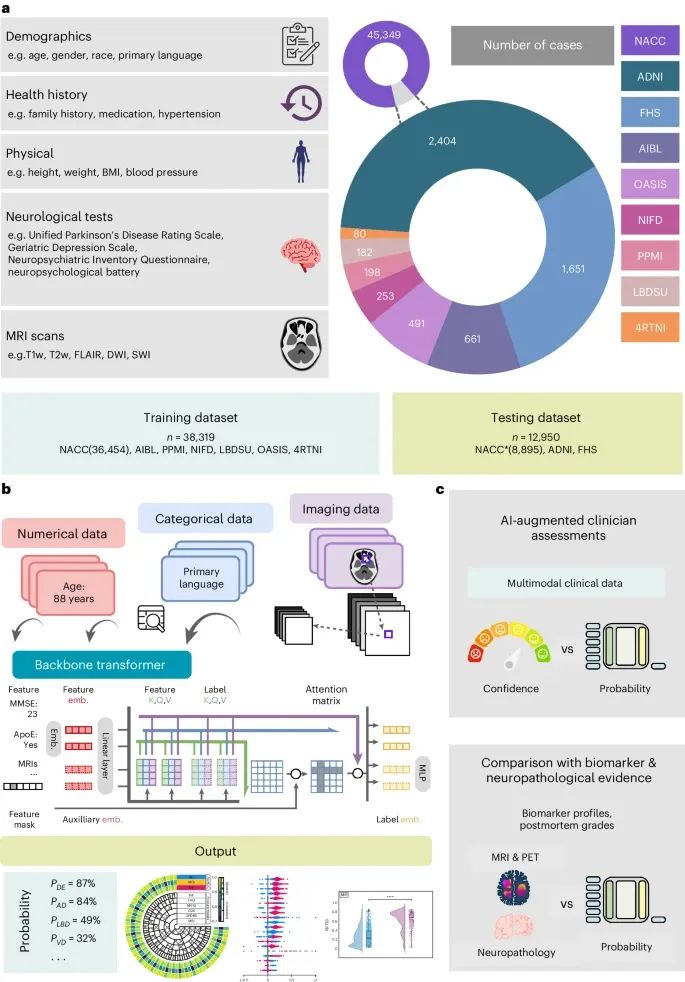
数据、模型架构与建模策略(Credit: Nature Medicine)
数据来源(Data Sources):研究的数据来自九个独立的队列,包括4RTNI、ADNI、AIBL、FHS、LBDSU、NACC、NIFD、OASIS和PPMI。这些数据集提供了多种多样的数据类型,包括个体人口统计学信息、健康历史、神经测试结果、身体和神经检查以及多序列MRI扫描 。在模型训练过程中,数据集NACC、AIBL、PPMI、NIFD、LBDSU、OASIS和4RTNI的数据被合并用于训练模型;ADNI和FHS数据集用于外部验证 。
模型架构(Model Architecture):该模型的架构基于Transformer,每种特征数据通过一种特定模式嵌入策略被处理为固定长度的向量,然后作为输入提供给变换器。一个线性层连接变换器和输出预测层 。为了处理数据不完整性,模型采用了随机特征掩码技术,这种技术在训练过程中模拟特征的任意缺失,提高了模型在不同数据可用性情况下的稳健性 。
建模策略(Modeling Strategy):该模型首先将不同类型的诊断数据转换为固定长度的向量,并通过变换器进行综合分析。变换器的自注意力机制能够有效处理序列数据,捕捉数据中的复杂关系 。为了验证模型的有效性,研究对比了AI模型辅助下和没有AI辅助的情况下,神经科医生和神经放射科医生的诊断表现。结果表明,AI模型显著提高了诊断准确性 。
模型性能
在区分正常认知、轻度认知障碍和痴呆症个体时,模型的AUROC达到了0.94。在ADNI和NACC数据集上的验证中,模型分别达到了0.94和0.96的AUROC,展示了其在不同数据集上的稳健性。
在数据不完整的情况下,模型仍能保持较高的预测准确性。例如,在ADNI数据集中,尽管69%的数据缺失,模型的加权平均AUROC仍达到0.91。这表明模型具有很强的抗缺失数据能力。
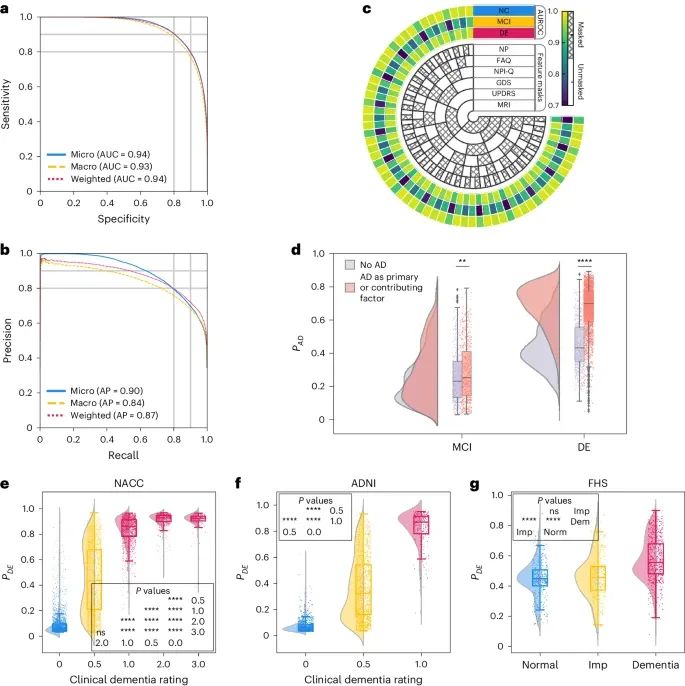
模型的表现(Credit: Nature Medicine)
ROC曲线和PR曲线(a, b):ROC曲线和PR曲线显示了模型在正常认知(NC)、轻度认知障碍(MCI)和痴呆症(DE)标签上的微平均、宏平均和加权平均计算结果。在测试集(包括未用于训练的NACC数据、ADNI和FHS数据)中,模型在分类NC、MCI和DE时表现出了强大的分类能力,AUROC(曲线下面积)达到0.94,AUPR(精确-召回曲线下面积)达到0.90。宏平均AUROC为0.93,AUPR值为0.84。加权平均AUROC和AUPR分别为0.94和0.87。这些指标显示了模型在不同认知状态下的稳健表现。
处理缺失数据的表现(c):示意图显示了在存在缺失数据的情况下模型的不同表现。内层同心圆表示在特定测试信息被省略(masked)或包含(unmasked)时的不同情境。三个外层同心圆表示模型在NC、MCI和DE标签上的AUROC表现。即使在MRI、统一帕金森病评分量表、老年抑郁量表、神经精神清单问卷、功能活动问卷等数据缺失的情况下,模型仍然能够产生可靠的评分。
预测AD概率的Raincloud图(d):Raincloud图展示了模型在NACC队列中对MCI和DE个体预测AD概率的情况。使用Kolmogorov-Smirnov(KS)双样本两侧检验比较AD是认知障碍因素的案例与非AD病因的案例。在MCI组(n=1,486)和DE组(n=4,085)中,AD因素的KS检验结果分别为KS=0.09, P=4.29×10^-3和KS=0.57, P<1×10^-200,表明AD因素的影响显著。
CDR评分与模型预测概率的分布(e–g):Raincloud图和小提琴图展示了在NACC、ADNI和FHS队列中,临床痴呆评分(CDR)与模型预测痴呆概率的关系。在NACC数据集中,CDR评分逐渐增加时,P(DE)逐渐增加,且在不同认知障碍谱系中的差异具有统计学显著性(P<0.0001)。在ADNI数据集中,P(DE)在基线CDR评分和较高评分之间显示出显著差异(P<0.0001)。在FHS数据集中,P(DE)在正常、认知受损和痴呆之间显示出显著差异(P<0.0001),但在正常与认知受损之间未显示显著差异。这表明模型在识别早期认知衰退时可能存在一定挑战。
模型与生物标志物一致性
模型预测结果与不同蛋白病变的关联通过尸检结果得到验证。例如,模型能够准确识别与TDP-43蛋白聚集相关的额颞叶变性(FTD)。在NACC数据集中,模型预测的FTD概率与MRI和FDG PET生物标志物显示的前额叶代谢减退和萎缩模式高度一致。
模型对阿尔茨海默病(AD)的预测概率与Aβ、tau和FDG PET生物标志物高度相关。在NACC和ADNI数据集中,Aβ、tau和FDG PET阳性组的AD概率显著高于阴性组,表明模型的诊断过程与当前AD诊断的ATN标准高度一致。
AI辅助临床评估
在随机选择的100个病例中,神经科医生在AI模型辅助下的评估比单独评估的AUROC高出26.25%。这表明AI模型能够显著提高临床医生的诊断准确性,尤其在复杂病例中。
AI辅助的评估在各类痴呆病因中均表现出显著的性能提升。例如,在帕金森病相关痴呆(PRD)中,AI模型的辅助使得AUROC提升了69%,在创伤性脑损伤(TBI)中,AUROC提升了72%。
模型在混合痴呆病例中的表现
研究发现,模型在处理混合痴呆病例时表现出色,平均AUROC达到了0.78。这表明模型不仅能够识别单一病因,还能有效处理多种病因共存的复杂情况。
在两种病因共存的情况下(如AD和VD共存),模型的AUROC为0.73,表现出较高的诊断准确性。研究显示,AI模型能够在不同病因之间进行有效区分,并提供准确的诊断建议。
该研究展示了一种综合多模态数据的AI模型,能够有效区分多种痴呆病因,提供个体化的诊断信息。尽管研究结果表明模型在多个独立队列中具有较高的鲁棒性和准确性,但其在更广泛的人群和临床环境中的通用性仍需进一步验证。此外,未来的研究应进一步评估该模型在临床实践中的实际应用效果,包括其在早期诊断和个性化治疗中的潜力。
在实际应用中,该AI模型有望显著提升痴呆症的诊断精度和患者护理质量。通过整合多种数据源,模型不仅能够提供准确的诊断,还能为临床医生提供决策支持,帮助制定个性化的治疗方案。未来,随着更多数据的积累和技术的进步,AI在医疗领域的应用将越来越广泛,为应对复杂的医疗挑战提供新的解决方案。
总之,该AI模型的开发和应用为痴呆症的鉴别诊断提供了一种新的工具,具有广阔的应用前景,有望显著提升痴呆症的诊断精度和患者护理质量。未来,随着技术的不断发展和完善,AI将在医疗领域发挥越来越重要的作用,为患者带来更多福音。
参考文献
https://www.nature.com/articles/s41591-024-03118-z
Xue C, Kowshik SS, Lteif D, Puducheri S, Jasodanand VH, Zhou OT, Walia AS, Guney OB, Zhang JD, Pham ST, Kaliaev A, Andreu-Arasa VC, Dwyer BC, Farris CW, Hao H, Kedar S, Mian AZ, Murman DL, O'Shea SA, Paul AB, Rohatgi S, Saint-Hilaire MH, Sartor EA, Setty BN, Small JE, Swaminathan A, Taraschenko O, Yuan J, Zhou Y, Zhu S, Karjadi C, Alvin Ang TF, Bargal SA, Plummer BA, Poston KL, Ahangaran M, Au R, Kolachalama VB. AI-based differential diagnosis of dementia etiologies on multimodal data. Nat Med. 2024 Jul 4. doi: 10.1038/s41591-024-03118-z. Epub ahead of print. PMID: 38965435.

