超好用的自信学习:1行代码查找标签错误,3行代码学习噪声标签
时间:2019-11-10 13:24:23 热度:37.1℃ 作者:网络
十三 发自 凹非寺
量子位 报道 | 公众号 QbitAI
你知道吗?就连ImageNet中也可能至少存在10万个标签问题。
在大量的数据集中去描述或查找标签错误本身就是挑战性超高的任务,多少英雄豪杰为之头痛不已。
最近,MIT和谷歌的研究人员便提出了一种广义的自信学习(Confident Learning,CL)方法,可以直接估计给定标签和未知标签之间的联合分布。
这种广义的CL,也是一个开源的Clean Lab Python包,在ImageNet和CIFAR上的性能比其他前沿技术高出30%。
这种方法有多厉害?举个栗子。

上图是2012年ILSVRC ImageNet训练集中使用自信学习发现的标签错误示例。研究人员将CL发现的问题分为三类:
1、蓝色:图像中有多个标签;
2、绿色:数据集中应该包含一个类;
3、红色:标签错误。
通过自信学习,就可以在任何数据集中使用合适的模型来发现标签错误。下图是其他三个常见数据集中的例子。

△目前存在于Amazon Reviews、MNIST和Quickdraw数据集中的标签错误的例子,这些数据集使用自信学习来识别不同的数据模式和模型。
这么好的方法,还不速来尝鲜?
什么是自信学习?
自信学习已然成为监督学习的一个子领域。
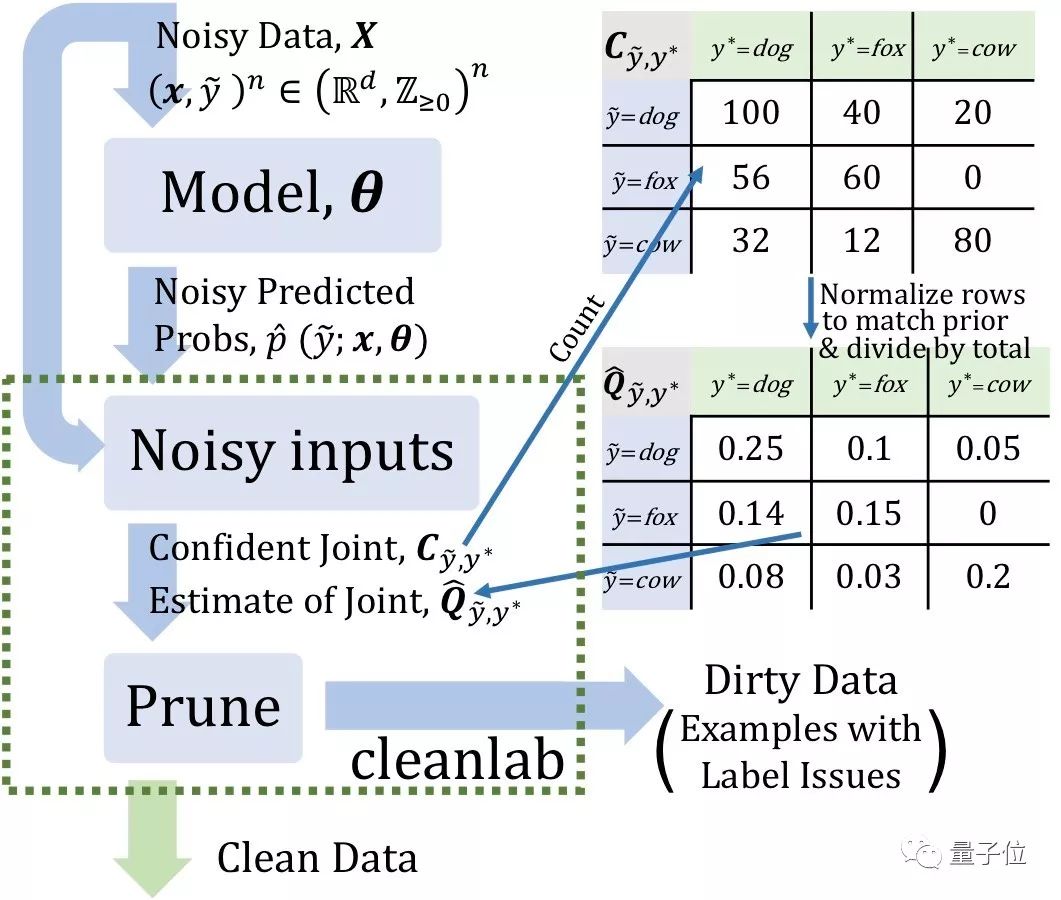
从上图不难看出,CL需要2个输入:
1、样本外预测概率;
2、噪声标签;
对于弱监督而言,CL包括三个步骤:
1、估计给定的、有噪声的标签和潜在的(未知的)未损坏标签的联合分布,这样就可以充分描述类条件标签噪声;
2、查找并删除带有标签问题的噪声(noisy)示例;
3、进行消除错误的训练,然后根据估计的潜在先验重新加权示例。
那么CL的工作原理又是什么呢?
我们假设有一个数据集包含狗、狐狸和奶牛的图像。CL的工作原理就是估计噪声标签和真实标签的联合分布(下图中右侧的Q矩阵)。

△左:自信计数的示例;右:三类数据集的噪声标签和真实标签的联合分布示例。
接下来,CL计数了100张被标记为“狗”的图像,这些图像就很可能是“狗”类(class dog),如上图左侧的C矩阵所示。
CL还计数了56张标记为狗,但高概率属于狐狸的图像,以及32张标记为狗,但高概率属于奶牛的图像。
而后的中心思想就是,当一个样本的预测概率大于每个类的阈值时,我们就可以自信地认为这个样本是属于这个阈值的类。
此外,每个类的阈值是该类中样本的平均预测概率。
轻松上手Clean Lab
刚才也提到,本文所说的广义CL,其实是一个Clean Lab Python包。而它之所以叫Clean Lab,是因为它能“clean”标签。
Clean Lab具有以下优势:
速度快:单次、非迭代、并行算法(例如,不到1秒的时间就可以查找ImageNet中的标签错误);
鲁棒性:风险最小化保证,包括不完全概率估计;
通用性:适用于任何概率分类器,包括 PyTorch、Tensorflow、MxNet、Caffe2、scikit-learn等;
独特性:唯一用于带有噪声标签或查找任何数据集/分类器标签错误的多类学习的软件包。
1行代码就查找标签错误!
# Compute psx (n x m matrix of predicted probabilities) on your own, with any classifier.
# Be sure you compute probs in a holdout/out-of-sample manner (e.g. cross-validation)
# Now getting label errors is trivial with cleanlab... its one line of code.
# Label errors are ordered by likelihood of being an error. First index is most likely error.
fromcleanlab.pruning importget_noise_indices
ordered_label_errors = get_noise_indices(
s = numpy_array_of_noisy_labels,
psx = numpy_array_of_predicted_probabilities,
sorted_index_method= 'normalized_margin', # Orders label errors
)
3行代码学习噪声标签!
fromcleanlab.classification importLearningWithNoisyLabels
fromsklearn.linear_model importLogisticRegression
# Wrap around any classifier. Yup, you can use sklearn/pyTorch/Tensorflow/FastText/etc.
lnl = LearningWithNoisyLabels(clf=LogisticRegression)
lnl.fit(X = X_train_data, s = train_noisy_labels)
# Estimate the predictions you would have gotten by training with *no* label errors.
predicted_test_labels = lnl.predict(X_test)
接下来,是Clean Lab在MNIST上表现。可以在这个数据集上自动识别50个标签错误。

原始MNIST训练数据集的标签错误使用rankpruning算法进行识别。描述24个最不自信的标签,从左到右依次排列,自顶向下增加自信(属于给定标签的概率),在teal中表示为conf。预测概率最大的标签是绿色的。明显的错误用红色表示。
传送门
项目地址:
https://github.com/cgnorthcutt/cleanlab/
自信学习博客:
https://l7.curtisnorthcutt.com/confident-learning
Reddit讨论:
https://www.reddit.com/r/MachineLearning/comments/drhtkl/r_announcing_confident_learning_finding_and/
— 完—
问卷福利!人工智能行业白皮书即将发布
量子位&IDC中国将联合发布「2019中国人工智能行业白皮书」,并于12月6日MEET大会重磅发布,特请小伙伴们填写一下问卷,谢谢大家支持~
填写福利:发布后第一时间获得白皮书,AI内参、大会观众票3折优惠券。 点击下图即可填写问卷、领取问卷福利:
榜单征集!三大奖项,锁定AI Top玩家
2019中国人工智能年度评选启幕,将评选领航企业、商业突破人物、最具创新力产品3大奖项,并于MEET 2020大会揭榜,欢迎优秀的AI公司扫码报名!
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !

