Front Med (Lausanne) :验证 SCCM 发现 VIRUS COVID-19 注册表的自动数据提取:实用的 EHR 导出路径 (VIRUS-PEEP)
时间:2023-10-23 11:35:43 热度:37.1℃ 作者:网络
研究背景:
新冠病毒病2019(COVID-19)大流行引发了迅速开发研究资源的需求。为响应全球对患者护理和结果方面强大的多中心临床数据的需求,美国危重病医学会(SCCM)在大流行早期创建了Discovery Viral Infection and Respiratory Illness Universal Study(VIRUS)COVID-19登记表。由于大流行浪潮的突然涌现以及随之而来的工作负担和人员不足,临床研究人员在从电子健康记录(EHR)中进行快速、可靠的手动数据提取方面遇到了困难。手动图表审核是用于回顾性研究的数据收集的黄金标准方法。然而,这个过程耗时,需要人力资源,在所有机构都不广泛可用。在大流行之前,利用直接数据库查询从EHR中进行自动数据提取被证明比手动数据提取更快且更少出错。尽管如此,与许多EHR系统中的数据高度复杂或分散有关的数据质量挑战使得自动提取容易受到影响。手动和自动提取都依赖于EHR,这是一个具有其自身偏见、错误和主观性的产物。尽管先前的研究已经涉及到了这些问题,但关于从EHR系统获取研究数据的最佳方法仍有待发现。因此,我们寻求评估使用VIRUS COVID-19登记表数据的自动化数据提取过程的可行性、可靠性和有效性。

研究材料和方法:
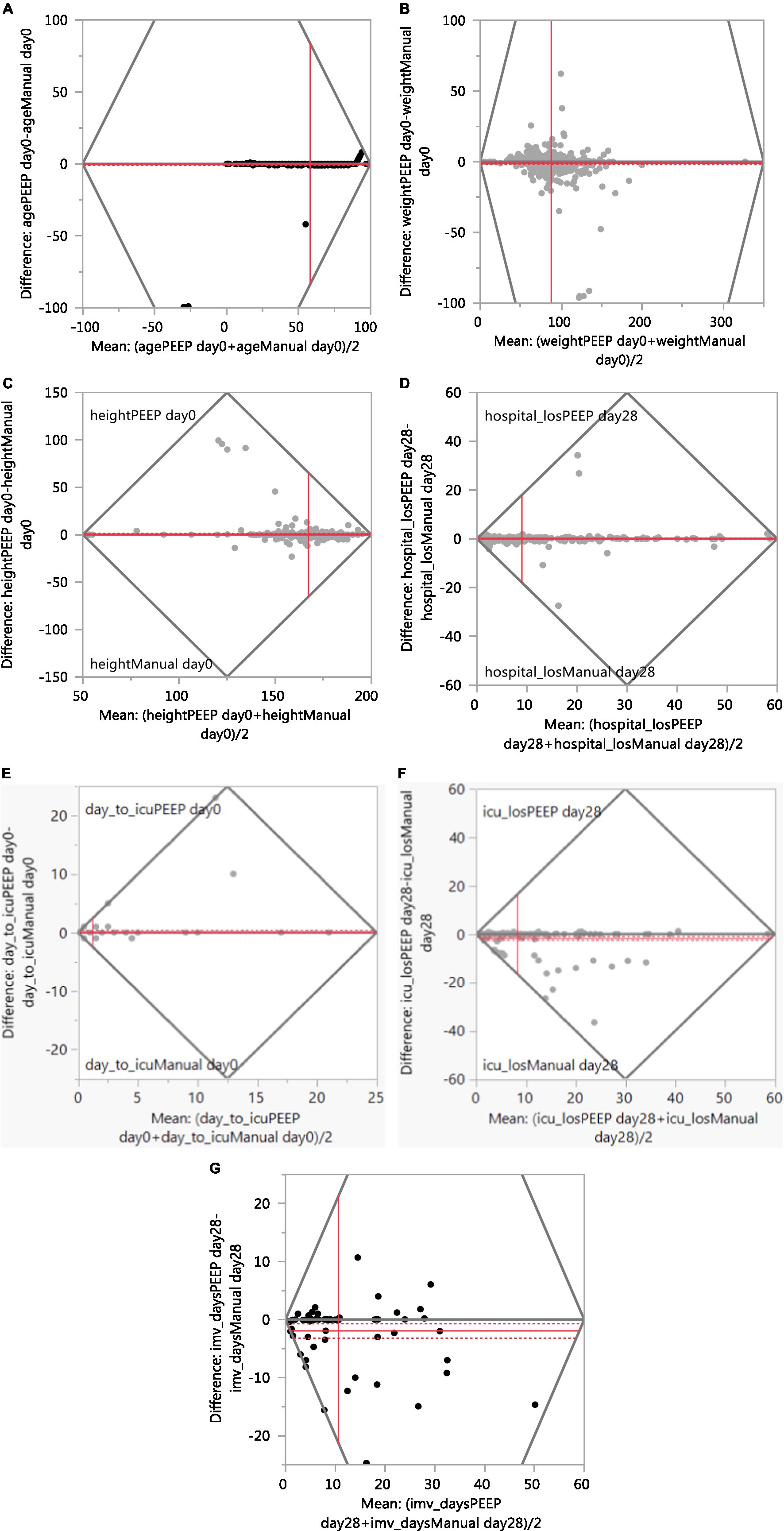
这项观察性研究包括参与SCCM Discovery VIRUS COVID-19登记表的医疗机构的数据。为了可行性数据集,选择了重要的人口统计学、合并症和结果变量,进行手动和自动提取。我们使用Cohen's kappa统计量来量化分类变量的一致程度。还对灵敏度和特异性进行了评估。使用Pearson相关系数和Bland-Altman图来评估连续变量的相关性。根据kappa统计,协议强度被定义为几乎完美(0.81-1.00)、显著(0.61-0.80)和中等(0.41-0.60)。Pearson相关被分类为微不足道(0.00-0.30)、低(0.30-0.50)、中等(0.50-0.70)、高(0.70-0.90)和极高(0.90-1.00)。
研究测量和主要结果:
该队列包括来自11个医疗机构的652名患者。对于分类变量,手动和自动提取之间的协议一致程度在13个变量中几乎完美(72.2%)(种族、族裔、性别、冠状动脉疾病、高血压、充血性心力衰竭、哮喘、糖尿病、ICU入院率、IMV率、HFNC率、ICU和医院出院状况),在五个变量中显著(27.8%)(慢性阻塞性肺病、慢性肾病、血脂异常/高血脂症、NIMV和ECMO率)。在连续变量中,三个(42.9%)变量(年龄、体重和住院时间)的相关性极高,四个(57.1%)连续变量(身高、入ICU天数、ICU住院天数和IMV天数)的相关性高。分类数据的平均灵敏度和特异性分别为90.7%和96.9%。
研究结论和相关性:
我们的研究证实了从EHR中获取数据的自动化过程的可行性和有效性。
原始出处:
Valencia Morales DJ, Bansal V, Heavner SF, Castro JC, Sharma M, Tekin A, Bogojevic M, Zec S, Sharma N, Cartin-Ceba R, Nanchal RS, Sanghavi DK, La Nou AT, Khan SA, Belden KA, Chen JT, Melamed RR, Sayed IA, Reilkoff RA, Herasevich V, Domecq Garces JP, Walkey AJ, Boman K, Kumar VK, Kashyap R. Validation of automated data abstraction for SCCM discovery VIRUS COVID-19 registry: practical EHR export pathways (VIRUS-PEEP). Front Med (Lausanne). 2023 Oct 4;10:1089087. doi: 10.3389/fmed.2023.1089087. PMID: 37859860; PMCID: PMC10583598.

