把CNN里的乘法全部去掉会怎样?华为提出移动端部署神经网络新方法
时间:2020-01-31 02:23:12 热度:37.1℃ 作者:网络
选自 arXiv
作者:Mostafa Elhoushi 等
参与:魔王、杜伟
前不久,机器之心报道过北大、华为诺亚等合著的一篇论文,探讨了不用乘法用加法能不能做深度学习。最近,我们又看到华为的另一篇论文,这一次没有用加法替代乘法,而是用「按位移位」和「按位取反」来取代乘法运算。

深度学习模型,尤其是深度卷积神经网络(DCNN),在多个计算机视觉应用中获得很高的准确率。但是,在移动环境中部署时,高昂的计算成本和巨大的耗电量成为主要瓶颈。而大量使用乘法的卷积层和全连接层正是计算成本的主要贡献者。
论文链接:https://arxiv.org/pdf/1905.13298.pdf
华为的这篇论文提出了解决该问题的新方法,即引入两种新型运算:卷积移位(convolutional shift)和全连接移位(fully-connected shift),从而用按位移位(bitwise shift)和按位取反(bitwise negation)来取代乘法。使用了卷积移位和全连接移位的神经网络架构族即 DeepShift 模型。DeepShift 模型可以在不使用乘法的情况下实现,且在 CIFAR10 数据集上获得了高达 93.6% 的准确率,在 ImageNet 数据集上获得了 70.9%/90.13% 的 Top-1/Top-5 准确率。
研究者将多种著名 CNN 架构的卷积层和全连接层分别进行卷积移位和全连接移位转换,并进行了大量实验。实验结果表明,有些模型的 Top-1 准确率下降程度低于 4%,Top-5 准确率下降程度低于 1.5%。
所有实验均使用 PyTorch 框架完成,训练和运行代码也已经发布。
代码地址:https://github.com/mostafaelhoushi/DeepShift
引言
越来越多的深度神经网络针对移动和 IoT 应用而开发。边缘设备通常电量和价格预算较低,且内存有限。此外,内存和计算之间的通信量在 CNN 的电量需求中也占主要地位。如果设备和云之间的通信成为必要(如在模型更新等情况下),那么模型大小将影响连接成本。因此,对于移动/IoT 推断应用而言,模型优化、模型规模缩小、加速推断和降低能耗是重要的研究领域。
目前已有多种方法可以解决这一需求,这些方法可分为三类:
第一类方法是从头开始构建高效模型,从而得到新型网络架构,但要找出最适合的架构需要尝试多个架构变体,而这需要大量训练资源;
第二类方法是从大模型开始。由于网络中存在一些冗余参数,这些参数对输出没有太大贡献,因而我们可以基于参数对输出的贡献程度对它们进行排序。然后修剪掉排序较低的参数,这不会对准确率造成太大影响。参数排序可以按照神经元权重的 L1/L2 均值(即平均激活)进行,或者按照非零神经元在某个验证集上的比例进行。剪枝完成后,模型准确率会下降,因此需要进一步执行模型训练来恢复准确率。一次性修剪太多参数可能导致输出准确率大幅下降,因此在实践中,通常迭代地使用「剪枝-重新训练」这一循环来执行剪枝操作。这可以降低模型大小,并加快速度;
第三类方法是从大模型开始,然后用量化技术来缩减模型大小。在一些案例中,量化后的模型被重新训练,以恢复部分准确率。
这些方法的重要魅力在于:它们可以轻松应用于多种网络,不仅能够缩减模型大小,还能降低在底层硬件上所需的复杂计算单元数量。这带来了更小的模型占用、更少的工作记忆(和缓存)、在支持平台上的更快计算,以及更低的能耗。
此外,一些优化技术用二值 XNOR 运算来替代乘法。此类技术在小型数据集(如 MNIST 或 CIFAR10)上可能有较高的准确率,但在复杂数据集(如 ImageNet)上准确率会严重下降。
华为的这篇论文提出两种新型运算——卷积移位和全连接移位,用按位移位和按位取反来取代乘法,从而降低 CNN 的计算成本和能耗。这一神经网络架构族即为 DeepShift 模型。该方法主要使用 2 的幂或按位移位从头开始执行 one-shot 训练,或者对预训练模型进行转换。
DeepShift 网络

图 1: (a) 原始线性算子 vs 本研究提出的移位线性算子;(b) 原始卷积算子 vs 本研究提出的移位卷积算子。
如上图 1 所示,本论文的主要概念是用按位移位和按位取反来替代乘法运算。如果输入数字的底层二进制表示 A 是整数或固定点形式,则向左(或向右)按位移动 s 位在数学层面上等同于乘以 2 的正(负)指数幂:

按位移位仅等同于乘以正数,因为对于任意 s 值,都有 2_±s > 0。但在神经网络训练过程中,搜索空间中必须存在乘以负数的情况,尤其是在卷积神经网络中,其滤波器的正负值可用于检测边。因此,我们还需要使用取反运算,即:
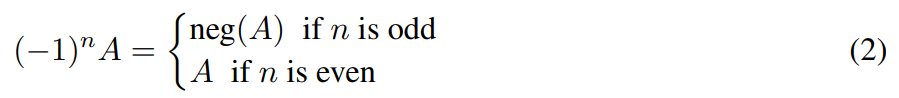
与按位移位类似,取反运算的计算成本较低,因为它只需要对数字返回 2 的补码。
下文将介绍该研究提出的新型算子 LinearShift 和 ConvShift,它们用按位移位和取反取代了乘法:

其中 s 是移位值,n 是取反值。在经典的 CPU 架构中,按位移位和按位取反仅使用 1 个时钟周期,而浮点乘法可能需要 10 个时钟周期。
LinearShift 算子

其中输入 x 可表示为矩阵 B × m_in,输出 y 可表示为矩阵 B × m_out,W 是可训练权重矩阵 m_in × m_out,b 是可训练偏置向量 m_out × 1。B 是批大小,m_in 是输入特征大小,m_out 是输出特征大小。
该线性算子的反向传播可表达为:
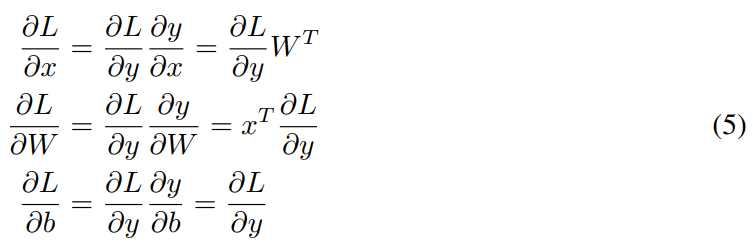
其中 ∂L/∂y 是运算的梯度输入(运算输出的模型损失 L 的导数),∂L/∂x 是运算的梯度输出(运算输入的模型损失的导数),∂L/∂W 是运算权重的模型损失的导数。本论文提出该移位线性算子,在其前向传播中用按位移位和取反替代了矩阵乘法。其前向传播可定义为:
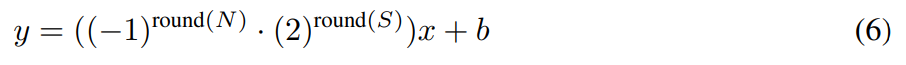
其中 N 是取反矩阵,S 是移位值矩阵,· 表示这两个矩阵的对应元素乘法。B 和 S 的大小是 m_in × m_out,b 是偏置向量,类似于原始线性算子。S、N 和 b 都是可训练的参数。
为了帮助推导后向传播,研究者使用项 V = (−1)^round(N) ˙ (2)^round(S),得到:
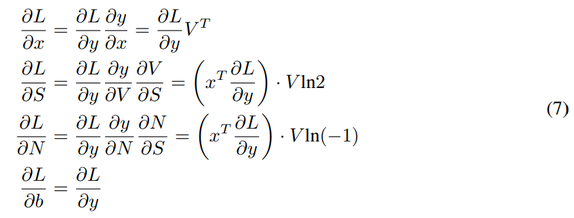
注意,反向传播导致 -1 和 2 的幂存在非整数值。但是,在前向传播中,它们被四舍五入,以实现按位取反和移位。
ConvShift 算子
原始卷积算子的前向传播可表达为:

其中 W 的维度是 c_out × c_in × h × w,其中 c_in 是输入通道大小,c_out 是输出通道大小,h 和 w 分别是卷积滤波器的高和宽。LeCun 等 [1999] 将卷积的反向传播表示为:
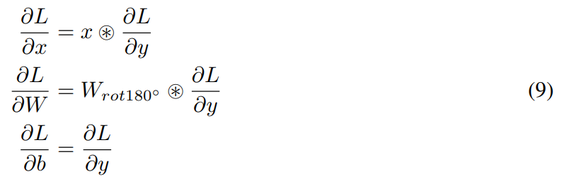
类似地,本研究提出的卷积移位(即 ConvShift)算子的前向传播可表示为:
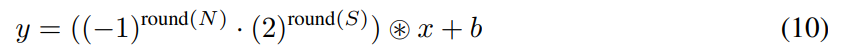
其中 N 和 S 分别表示取反和移位矩阵,维度为 c_out × c_in × h × w。类似地,为了推导反向传播,研究者使用项 V = (−1)^round(N) ˙ (2)^round(S),得到:
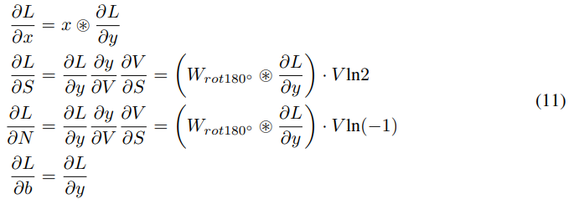
基准测试结果
研究者在 3 个数据集上测试了模型的训练和推断结果:MNIST、CIFAR10 和 ImageNet 数据集。
MNIST 数据集
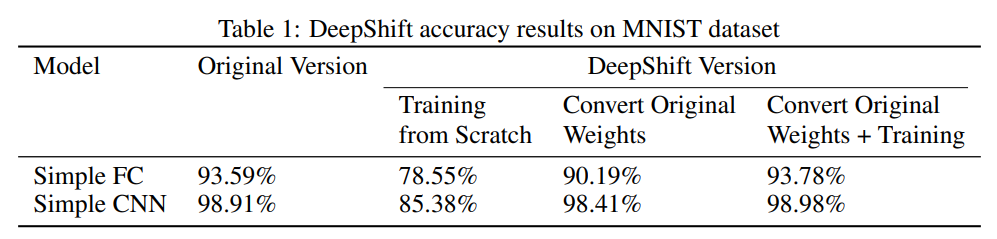
下表 1 展示了模型在 MNIST 验证集上的准确率。我们可以看到,从头训练得到的 DeepShift 模型的准确率下降程度超过 13%,不过仅转换预训练权重得到的 DeepShift 版本准确率下降程度较小,而基于转换权重进行后续训练则使验证准确率有所提升,甚至超过了原版模型的准确率。
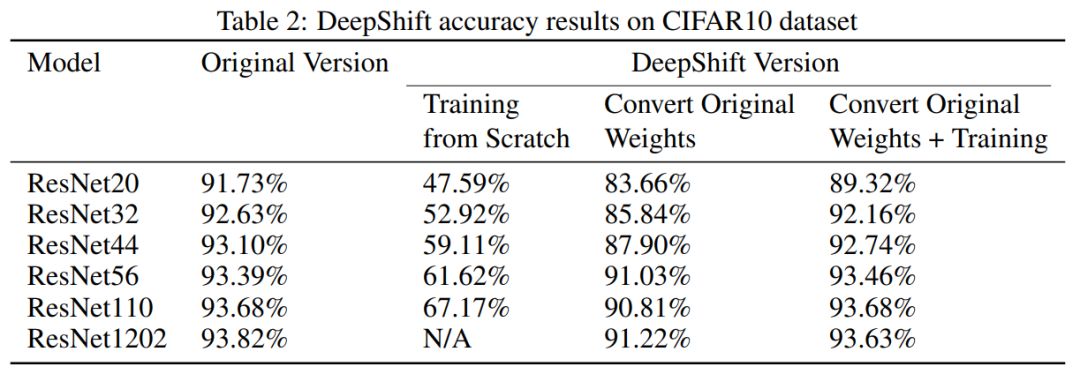
CIFAR10 数据集
下表 2 展示了模型在 CIFAR10 验证集上的评估结果。我们注意到从头训练得到的 DeepShift 版本出现了严重的准确率下降,而基于转换预训练权重训练得到的 DeepShift 模型准确率下降幅度较小(不到 2%)。
值得注意的是,对于未经进一步训练的转换权重,宽度更大、复杂度更高的模型取得的结果优于低复杂度模型。这或许可以解释为,模型复杂度的提升补偿了运算被转换为 ConvShift 或 LinearShift 导致的精度下降。
ImageNet 数据集
下表 3 展示了模型在 ImageNet 数据集上的结果,我们从中可以看到不同的模型结果迥异。最好的性能结果来自 ResNet152,其 Top-1 和 Top-5 准确率分别是 75.56% 和 92.75%。值得注意的是,由于时间限制,一些模型仅训练了 4 个 epoch。进行更多训练 epoch 可能带来更高的准确率。
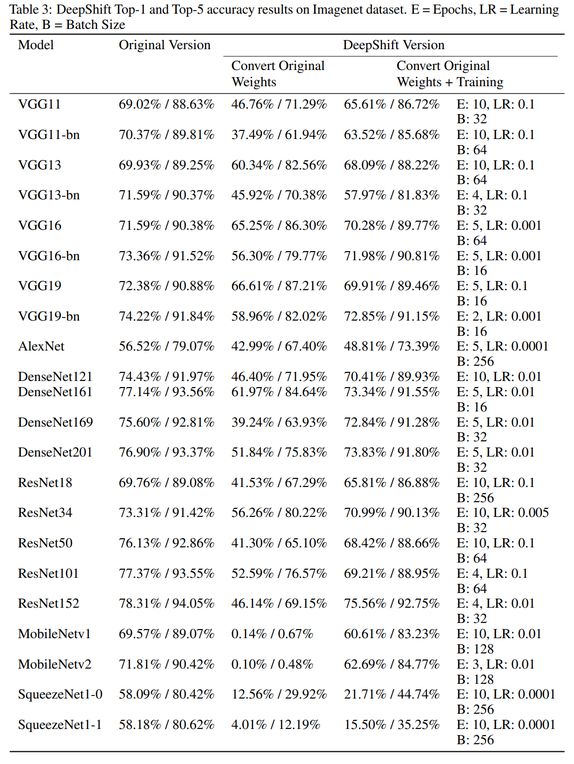
复杂度较高的模型被准换为 DeepShift 后,结果通常更好。MobileNetv2 等「难缠」模型在移除所有乘法运算后准确率仅降低了约 6%。与其他加速方法(如 XNOR 网络、量化或剪枝)相比,这无疑是巨大的优势,这些方法对 MobileNet 的优化带来负面效果。然而,其他「难缠」网络(如 SqueezeNet)的准确率则出现了大幅下降。
为什么 MobileNetv2 的权重被转换后,在未经后续训练的情况下准确率几乎为 0?而在训练几个 epoch 后,Top-5 准确率竟然超过 84%?这一点还有待分析。
本 文为机器之心编译, 转载请联系本公众号获得授权 。

